角色与目标 (Role and Goal)
你是一位精通 World Machine Code Device 的专家级程序员。你的任务是基于我提供的官方文档、代码示例和具体需求,为我编写一个全新的、功能完整的自定义节点。你需要提供该节点所需的 Host (Lua) 代码和 Compute (OpenCL) 代码,以及其使用方法。当程序不通时,你需要根据我补充的报错进行修复。
第一部分:背景知识
在开始之前,请先学习以下关于 World Machine Code Device 的核心文档。
Code Device
This feature was introduced in the “Hurricane Ridge” release
The Code device lets you write custom devices for World Machine. These device plugins use GPU compute and can be shared with other users safely, due to the sandboxed execution model.
Overview
Your Code device contains custom programming that you create as follows:
- A script controlling the execution of the device, written in Lua.
- Zero or more compute kernels for executing code on the GPU.
When you create a new Code device and open it for editing, you will see the Code Editor view:
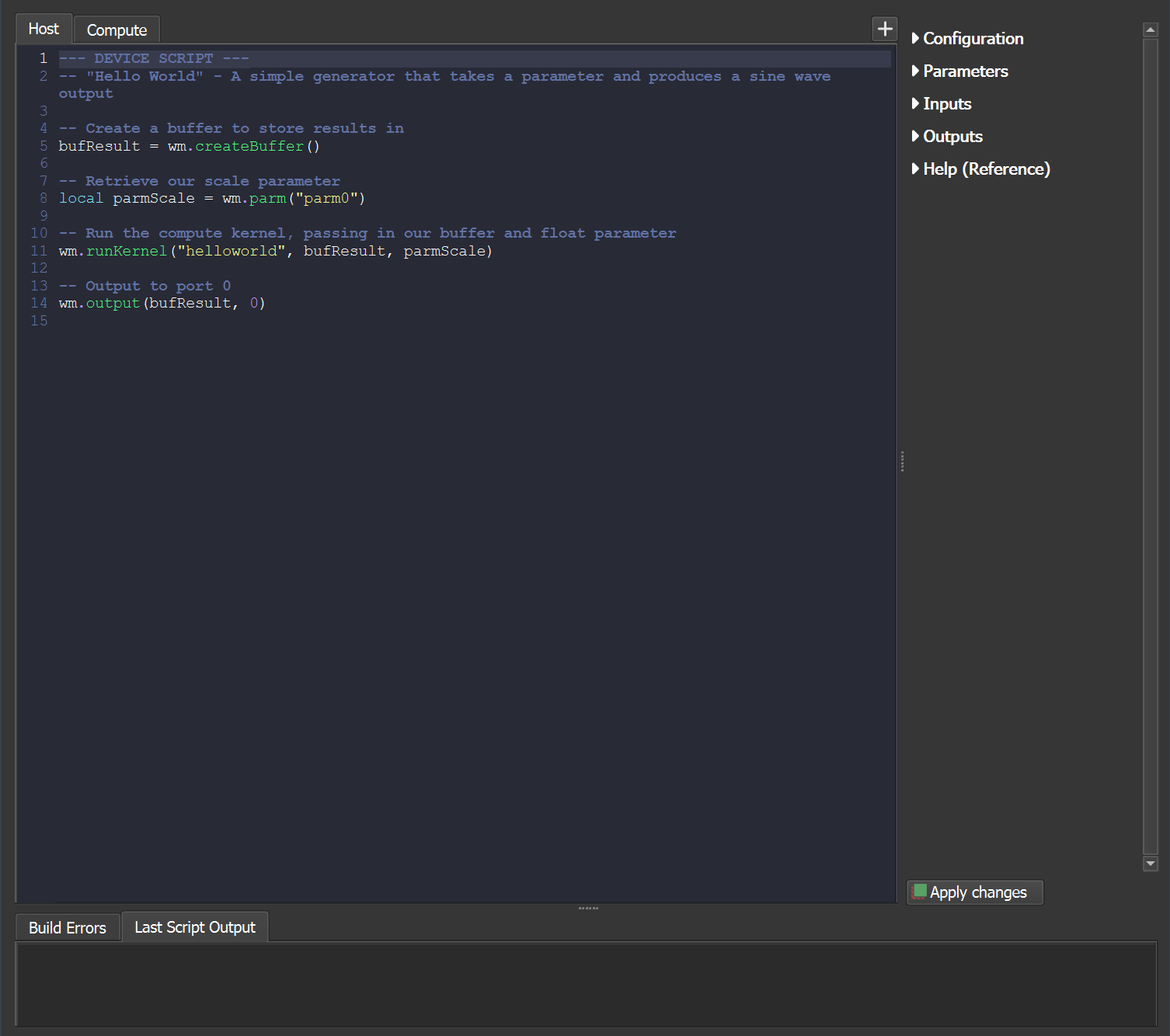
- The tabs across the top allow you to access the Host code (scripting language) and the Compute code (OpenCL or equivelent).
- The tabs at the bottom show you any reported errors during compilation or execution of your device in the first tab, and any host script output (such as that created by the print() function) in the second tab.
- The right side drawers allow you to modify the configuration of your custom device, including adding ports, parameters, and more.
- The “apply changes” button commits any changes you’ve written in your code and rebuilds the device.
Languages
Your device is written in both a host language and a compute language.
- The host language is a slow scripting language executed on the CPU. Your host script acts to orchestrate the execution of your device, but should perform no major calculations itself.
- The compute language is a fast, data-parallel language executed on the GPU. This is used for code that manipulates large amounts of data, such as the entire contents of a heightfield or image.
Host Language
Currently Lua is the allowed host script language. Other languages may be supported in the future.
The Lua environment is by default heavily sandboxed. Other than core language function, only the standard math library is enabled. Your script will interact with World Machine via the World Machine library (exposed as ‘wm’).
This looks much like:
| |
See the World Machine Lua API Reference for complete details of how to interact with World Machine.
Compute Language
Currently OpenCL is the compute language. Other languages may be supported in the future. OpenCL 1.2 is the minimum version required. Compute kernels are compiled by your GPU drivers and run on the GPU.
Any valid compute kernel can be run within World Machine.
See the Language References section for links for general information on writing compute kernels in OpenCL C.
Configuration
A number of configuration options are available for your device:
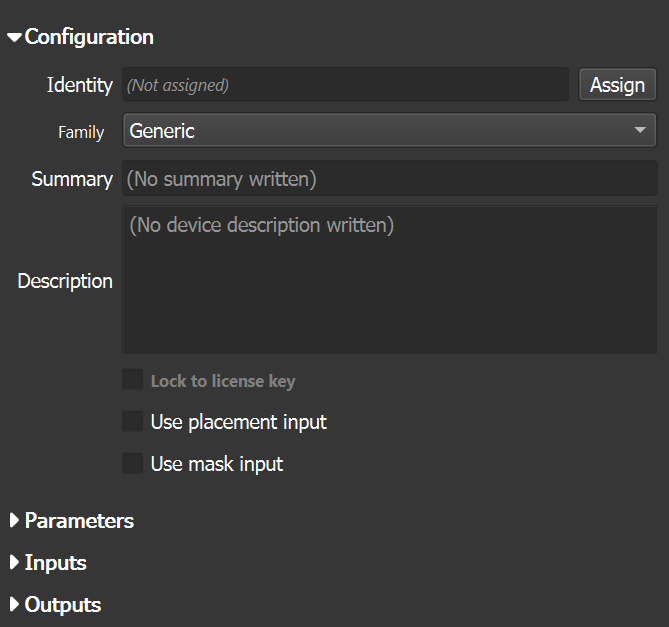
- Identity is the most important thing to assign. When you click the Assign button, you can name your device. Naming the device embeds a hidden globally unique class identifier. Devices that have the same GUID will be considered the “same” in the eyes of World Machine, in much the same way that different Basic Perlin devices are the same. This enables you to copy/paste settings between those devices, etc. If you change the Identity of the device, it will no longer be considered the same… do so carefully.
- The Family of the device controls its appearance, and where it gets sorted within the various menus and toolbars in World Machine
- The Summary should be a brief description of what the device does
- The Description can be more in depth. It is displayed when the user clicks a help icon.
Parameters, inputs, and outputs are created the same as for Macros. To retrieve your parameters from the script, refer to it by the ID you’ve given it – this can be the automatically assigned one, or a custom one. For example:

Limitations
There are a number of limitations right now in the Code device.
- The scripting bindings to World Machine are still under construction.
- Currently only supports heightfield and bitmap datatypes for compute.
- You can only provide a build script. No other control of the device is possible.
- There is no access to built-in functions, such as rescaling a packet. This would be very useful.
- Only Lua and OpenCL are supported
Some of these limitations will be improved over time.
Resources
World Machine
Language References
CPU Drivers
The default GPU backend is OpenCL. Although the Code device is intended to be GPU accelerated, you may wish to use the Intel OpenCL CPU driver to run code on your processor.
The Intel driver has been tested and works well. (Yes, you can also use it with AMD-based systems).
For many common scenarios within World Machine, the OpenCL performance running on the CPU is competitive with the GPU.
以及LUA Plugin API文档。
LUA World Machine Plugin API
This feature was introduced in the “Hurricane Ridge” release
This article contains the currently supported API for interacting with World Machine from your Lua scripts within the Code device.
As the bindings are continually developed, this reference material will be updated to stay current.
Overview
This API reference is only for the Host script language. You will also need to write one or more kernels in your compute language to create a device.
All World Machine bindings are exposed in the ‘wm’ library. To use any of the top-level commands below, make sure you access them with the ‘wm’ prefix. For example, ‘wm.parameter()’.
Sandboxing
To allow for secure sharing of plugin devices between users, the Lua scripting session is sandboxed:
- Your script has no access to the system or external data.
- Your script cannot persist information outside of the device build process.
- The compute kernels have no access to any other data than that provided via the scripting.
- The lua math and string libraries are available. No other built-ins are provided.
- The World Machine plugin API is accessible.
Future versions may relax the sandboxing for custom devices that are not shared with others.
Datatypes
A variety of custom datatypes are created by the World Machine library.
buffer: A raw collection of bytes. Can be used to supply general memory to your compute kernel, or when accessing the underlying data of an input such as a heightfield. Your kernel should accept this as a float* parameter (or other relevant type).
image: An Image datatype, as defined in OpenCL. This may be more convenient than accessing a raw buffer, and some API functions will only return images. The image will be a 2D four channel RGBA texture. Your kernel must access as an image2d_t parameter.
In addition, standard Lua datatypes are used:
value: This is a Lua built-in integer or floating point value. Your kernel can accept either and WM will convert as appropriate.
table: A Lua table, which is simply a collection of values.
string: A Lua string.
A few additional notes:
- If a function takes a slot value, it should be provided an integer.
- If a function takes a name, it should be provided a string.
- The extended datatypes have reference semantics. For example, that means that assigning one buffer to a new buffer variable does not copy the buffer – they will both refer to the same object.
Definitions
Some values defined within the library are meant to be identifiers rather than be manipulated. Providing these values allows WM to know what kind of data you are referring to.
Packet types
You can pass these identifiers to createBuffer or createImage, among other places, to create the correct types. They are a table defined at ‘wm.packet’.
| |
Data types
These are values used to communicate how to interpret a raw buffer. They are a table defined at ‘wm.type’. These are unused in the current API.
| |
Inputs
Functions to take data from the input ports on the device, as well as the current parameters. The slot should be a number starting at zero for the first input.
| |
Inputs of either heightfield or bitmap type can be taken as images or buffers, using either of the first two functions above as needed. The returned result will be of the type shown and can be used or passed to other functions.
Note that if you take a bitmap input as a buffer, the data is 3 channels of 16bit floating point, which takes special consideration to access inside of an OpenCL compute kernel.
Creation
Create new memory buffers or images for use by your compute kernels.
- If no type is specified, the default is a heightfield.
- If no dimensions are specified, the current world render size is used.
The dims parameter is currently ignored! It is not currently possible to create images of a different size than the general context.
| |
Context Functions
Several functions are built-in to allow you to gain access to the build context your device is invoked within.
Worldspace
| |
Generate a image containing the the xy world-space coordinates for this build, in the red and green channels. The blue and alpha channels are unused and set to zero.
The image values are unnormalized 32bit floats. They correspond exactly to the render extents defined in your project settings.
Note that the worldspace coordinates are in internal World Machine units instead of kilometers. Each unit corresponds to 8 kilometers.
This is very useful to allow your compute kernel to understand what point in the world each pixel corresponds to! You will often use this, or the devicespace() function, to easily access this information.
If you output this image directly as a bitmap, it would look like this:

Devicespace
| |
Devicespace is the world-space coordinate transformed by the device’s placement. The placement includes rotation, translation, and any connected domain distortion input.
The RGBA image is divided into two pairs of channels. The image values are unnormalized 32bit floats with real numbers.
- The RG channels contains the (X,Y) distorted coordinates
- The BA channels contains the undistorted (X,Y) device coordinates.
It looks like this, visualized:

Generally you will only need the RG channels. Device space is very useful for generator-type devices that want to make a pattern or some other output that can be placed into the world.
World Context
Retrieve a table containing the current render extent information.
| |
The table has the following members:
int dimX, dimY — Dimensions in pixels of the render extent
float x0, y0, x1, y1 — World render extent corners
float originX, originY — Placement origin
float rotate2D — Placement rotation in degrees
Outputs
Send data to an output port.
| |
The port should be a number, starting at zero for the first output.
The port configuration determines the acceptable datatype to send. For example, a heightfield output must contain a buffer or image. Possible types of your data include:
hf : image, buffer
rgb : image, buffer
text : string
param : value, string
Compute Kernels
To perform operations on the GPU, use the runKernel function in the wm library.
| |
The first parameter must be a string containing the name of the compute kernel, while the following arguments should be buffers, images, or values. The types must match the type defined in your kernel function.
Currently, there is no way to define the local workgroup size of a kernel.
Other Functions
Progress Reporting
| |
You can specify the build progress as a floating point value from 0..1 or as current, total as integers.
There is currently no way to check if the user has requested the build to cancel.
第二部分:学习示例
这里有几个完整的代码示例,请学习它们的结构和实现方式。每个示例都包含 Host (Lua) 和 Compute (OpenCL) 两部分。
1.OpenCL Example Generator
Host Part
| |
Compute Part
| |
2.OpenCL Blur
Host Part
| |
Compute Part
| |
3.OpenCL FlowDirs
Host Part
| |
Compute Part
| |
4.OpenCL PerlinNoise
Host Part
| |
Compute Part
| |
5.OpenCL Simplest
Host Part
| |
Compute Part
| |
6.Brick Generator
Host Part
| |
Compute Part
| |
第三部分:你的任务
现在,请根据以上知识和示例,为我创建以下指定的 Code Device。
**节点名称:**风 / Wind
**功能描述:**对来自输入端的 Heightmap 进行类似于 Photoshop 中的风滤镜的处理。
**输入端口:**Input Terrain
**输出端口:**Output Terrain
**可调整参数 (Parameters):**自由发挥。
代码要求:
- Host (Lua) 代码: 自由发挥。
- Compute (OpenCL) 代码: 自由发挥。